
What a nicely-designed resource for information about color theory along with some material about its use in UX and data visualization!
Tag: vision
-
An Interactive Guide to Color & Contrast
-
The Realities And Myths Of Contrast And Color
From Andrew Somers, a great primer on how color vision works and how illuminated display technology maps perception to luminance contrast, color gamut, etc. Especially useful is his writeup of not only WCAG 2’s limitations for determining proper contrast for meeting accessibility needs but also the upcoming standards like APAC (Accessible Perceptual Contrast Algorithm) that will pave the way for more useful and relevant a11y standards.
-
Why we’re blind to the color blue
If you’re super nerdy and experienced with using Photoshop’s individual color channels to make enhancements or custom masks, you might have noticed that the blue channel has very little influence on the overall sharpness of an RGB image — it never occurred to me that this is inherently a function of our own human eyesight, which is unable to properly focus on blue light, in comparison to other wavelengths!
I like how the paper from the Journal of Optometry that this article links to straight up dunks on our questionably-designed eyeballs:
In conclusion, the optical system of the eye seems to combine smart design principles with outstanding flaws. […] The corneal ellipsoid shows a superb optical quality on axis, but in addition to astigmatism, it is misaligned, deformed and displaced with respect to the pupil. All these “flaws” do contribute to deteriorate the final optical quality of the cornea. Somehow, there could have been an opportunity (in the evolution) to have much better quality, but this was irreparably lost.
This also made me wonder if this blue-blurriness has anything to do with the theory that cultures around the world and through history tend to develop words for colors in a specific order, with words for “blue” appearing relatively late in a language’s development. Evidently that’s likely so, because hard-to-distinguish colors take longer to identify and classify, even for test subjects who have existing words for them!
-
Kittydar
Hmm, @harthvader has written some impressive neural network, machine learning, and image detection stuff, shared on her GitHub — wait, she’s combined these things into a JavaScript cat-detecting routine?! Okay, that wins.
var cats = kittydar.detectCats(canvas);
console.log(“there are”, cats.length, “cats in this photo”);
console.log(cats[0]);
// { x: 30, y: 200, width: 140, height: 140 }You can try out Kittydar here.
(Via O’Reilly Radar)
-
Google X Cat Image Recognition

The Internet has become self-aware, but thankfully it just wants to spend some time scrolling Tumblr for cat videos. From the NY Times, How Many Computers to Identify a Cat? 16,000:
[At the Google X lab] scientists created one of the largest neural networks for machine learning by connecting 16,000 computer processors, which they turned loose on the Internet to learn on its own.
Presented with 10 million digital images found in YouTube videos, what did Google’s brain do? What millions of humans do with YouTube: looked for cats. The neural network taught itself to recognize cats, which is actually no frivolous activity.
(Photo credit: Jim Wilson/The New York Times)
-
Simulated Heat Mapping for Computer Vision
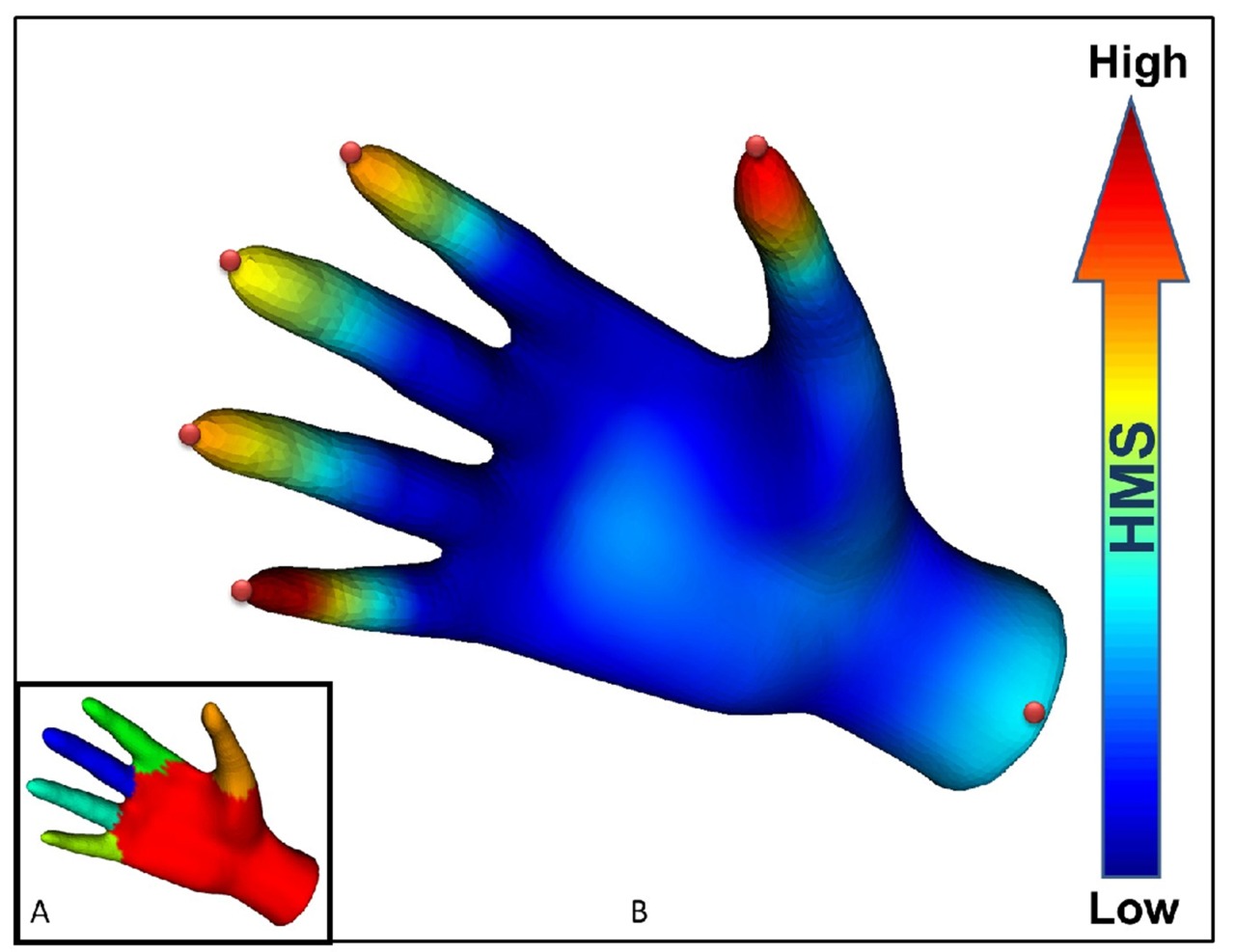
A new approach to computer vision object recognition: simulated heat-mapping:
The heat-mapping method works by first breaking an object into a mesh of triangles, the simplest shape that can characterize surfaces, and then calculating the flow of heat over the meshed object. The method does not involve actually tracking heat; it simulates the flow of heat using well-established mathematical principles, Ramani said. …
The method accurately simulates how heat flows on the object while revealing its structure and distinguishing unique points needed for segmentation by computing the “heat mean signature.” Knowing the heat mean signature allows a computer to determine the center of each segment, assign a “weight” to specific segments and then define the overall shape of the object. …
“A histogram is a two-dimensional mapping of a three-dimensional shape,” Ramani said. “So, no matter how a dog bends or twists, it gives you the same signature.”
In other words, recognizing discrete parts (like fingers or facial features) of an object in front of the camera should be much more accurate with this approach than with older techniques like simple edge detection. Uses for real-time recognition are apparent (more accurate Dance Central!), but it seems like this would also be a boon for character animation rigging?
(Via ACM TechNews)
-
Herman Melville on the Nature of Color
From Moby Dick, chapter 42, “The Whiteness of the Whale”:
Is it that by its indefiniteness it shadows forth the heartless voids and immensities of the universe, and thus stabs us from behind with the thought of annihilation, when beholding the white depths of the milky way? Or is it, that as in essence whiteness is not so much a color as the visible absence of color, and at the same time the concrete of all colors; is it for these reasons that there is such a dumb blankness, full of meaning, in a wide landscape of snows – a colorless, all-color of atheism from which we shrink? And when we consider that other theory of the natural philosophers, that all other earthly hues – every stately or lovely emblazoning – the sweet tinges of sunset skies and woods; yea, and the gilded velvets of butterflies, and the butterfly cheeks of young girls; all these are but subtile deceits, not actually inherent in substances, but only laid on from without; so that all deified Nature absolutely paints like the harlot, whose allurements cover nothing but the charnel-house within; and when we proceed further, and consider that the mystical cosmetic which produces every one of her hues, the great principle of light, for ever remains white or colorless in itself, and if operating without medium upon matter, would touch all objects, even tulips and roses, with its own blank tinge – pondering all this, the palsied universe lies before us a leper; and like wilful travellers in Lapland, who refuse to wear colored and coloring glasses upon their eyes, so the wretched infidel gazes himself blind at the monumental white shroud that wraps all the prospect around him. And of all these things the Albino Whale was the symbol. Wonder ye then at the fiery hunt?
-
Cryptochrome
Research continues on whether humans (and other animals) have the ability to perceive magnetic fields:
Many birds have a compass in their eyes. Their retinas are loaded with a protein called cryptochrome, which is sensitive to the Earth’s magnetic fields. It’s possible that the birds can literally see these fields, overlaid on top of their normal vision. This remarkable sense allows them to keep their bearings when no other landmarks are visible.
But cryptochrome isn’t unique to birds – it’s an ancient protein with versions in all branches of life. In most cases, these proteins control daily rhythms. Humans, for example, have two cryptochromes – CRY1 and CRY2 – which help to control our body clocks. But Lauren Foley from the University of Massachusetts Medical School has found that CRY2 can double as a magnetic sensor.
Vision is amazing, even more so when you take into account the myriad other things that animals and insects can detect beyond just our “visible” EMF spectrum. See also: box jellyfish with their surprisingly complex (and human-like) set of 24 eyes.
-
Hokusai Glasses

Megana-ya (Seller of Eyeglasses), by Hokusai, circa 1811-1814, part of a incredibly great collection of health-related Japanese woodblock prints housed at the University of California, San Francisco. Having recently bought a new pair of glasses, I can relate.
(Via Pink Tentacle)
-
iPad Light Paintings
This film explores playful uses for the increasingly ubiquitous ‘glowing rectangles’ that inhabit the world.
We use photographic and animation techniques that were developed to draw moving 3-dimensional typography and objects with an iPad. In dark environments, we play movies on the surface of the iPad that extrude 3-d light forms as they move through the exposure. Multiple exposures with slightly different movies make up the stop-frame animation.
We’ve collected some of the best images from the project and made a book of them you can buy: http://bit.ly/mfmbook
Read more at the Dentsu London blog:
http://www.dentsulondon.com/blog/2010/09/14/light-painting/
and at the BERG blog:
http://berglondon.com/blog/2010/09/14/magic-ipad-light-painting/From Dentsu London, Making Future Magic:
We use photographic and animation techniques that were developed to draw moving 3-dimensional typography and objects with an iPad. In dark environments, we play movies on the surface of the iPad that extrude 3-d light forms as they move through the exposure. Multiple exposures with slightly different movies make up the stop-frame animation.
Take that, Picasso.